





I am in the fortunate position of working in both academia and industry. In addition to my work at SnapLogic, I am a Professor of Computer Science at the University of San Francisco and I have worked on research in distributed systems, parallel programming, OS kernels, and programming languages for the last 20 years. Having these two roles has been mutually beneficial. I am able to apply my research to real world systems and I bring back that experience to the classroom. At SnapLogic, I have worked on advancing our product technology and most recently I was on the original architecture team for our new cloud-based integration product, which is a sophisticated distributed system. Now that we have released the product we can discuss many of the technical aspects and design decisions of the system.
In developing our Integration Platform as a Service (iPaaS) at SnapLogic, we reevaluated some of the core design principles found in traditional integration products that were a carry over from the early ETL days. One of our more profound architecture innovations is to employ JSON-like documents as the primary means for transporting data from Snap to Snap in a Pipeline. Older integration technologies were record-oriented in nature, which fit well to the relational database world at the time. However, today we see hierarchical formats such as JSON and XML are used both a the service interface level, such as REST and SOAP, and at the datastore level, such as in MongoDB.
Using Documents as our native data type brings several advantages both to data processing and to end users:
-
Documents are a better match to modern web services.
-
Documents result in more succinct Pipelines.
-
A document model allows Pipelines to be loosely coupled.
-
A document model allows for greater Pipeline reuse.
- Documents are a superset of records.
Modern Web Services
While some web services still use SOAP, an increasing number of RESTful interfaces use JSON as the data format for requests and replies. In either case, the data is hierarchical. Our support for documents allows our Snap endpoints to directly consume hierarchical data in native format and send it on to downstream Snaps in a Pipeline. This means that there is no requirement to flatten data into records or to turn a JSON document in a string or BLOB type. This native support allows all Snaps, such as Filter, Join, Sort, etc., to make decisions based on any field, possibly nested, within a document. The resulting document data can then be sent directly to an output Snap that possibly connects to another web service that consumes JSON. Our native document model makes it easy to process modern web data in its native format.
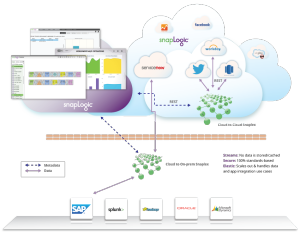
Although XML and JSON are both hierarchical, we are noticing that an increasing number of web services and APIs are exposing data in JSON formats because of its light weight and more compact representation. XML tends to bloat up data significantly with its meta tag encapsulations.
Succinct Pipelines
Our document model ultimately leads to more succinct Pipelines because it is not necessary to translate JSON or XML into flat records, then do the processing, and finally convert records back into JSON or XML. This allows users to focus on processing data and not on translating data formats, making working in SnapLogic more productive and less error prone. Fewer data translation steps also improves pipeline performance in terms of both throughput and latency.
Loose Coupling
The previous generation of integration products connected data flow components via typed links. This means that to connect one component to another, all of the output fields and types needed to be correctly linked to the input fields and types of the destination component. This mapping is needed between every component in a dataflow graph. While this coupling leads to a certain amount of type safety, it is also very cumbersome to manipulate Pipelines connected this way. In fact, SnapLogic has a patent pending on Predictive Field Linking in order to ease the construction of Pipelines that are based on strict field linking.
Since our primary data type is a document, almost all Snaps consume or produce documents. Connecting Snaps no longer requires field linking. This allows users to get pipelines up and running more quickly as you can simply connect Snaps, try them out, and rearrange them. Explicit field mapping can still be achieved; for example, the field first_name can be mapped to FirstName, but that is now done is a separate Mapping Snap. This has the added benefit of being able to encapsulate field mappings so that they can be reused easily in the same Pipeline or in different Pipelines.
Pipeline Reuse
Related to loose coupling, the document model better supports Pipeline reuse. Without strict field linking, nested pipelines are much easier to assemble through reuse of other pipelines. In a sense we have moved to a dynamically typed approach from a statically typed approach as found in programming languages. The dynamic approach leads to more compact pipelines which are easier to interconnect. This ease of interconnection also promotes unit testing of sub-pipelines so that correct execution can be be achieved more quickly.
Documents as Records
At SnapLogic we recognize that while modern web services and datastores are heading toward JSON, businesses still use relational databases for normalized, transactional data. The great thing about documents is that they are a superset of relational records. When converting a record into a document we combine the column names from the schema with the field data to create a key/value document. This allows us to consume records and output records as needed, but still get all the advantages of the document model. Furthermore, we support traditional ETL operations such as JOIN, AGGREGATE, and SORT on documents. This allows primarily relational data to be treated seamlessly, but also extends these ETL operations in a way that support hierarchical documents.
Conclusion
In response to changing integration end points and data formats, we have redesigned many aspects of how integration works in our new Integration Platform as a Service. Our JSON-centric approach embraces modern web interfaces and seamlessly supports relational data. This native support for documents is one of the many architectural innovations we have developed to help businesses connect both web services and traditional datastores.




