





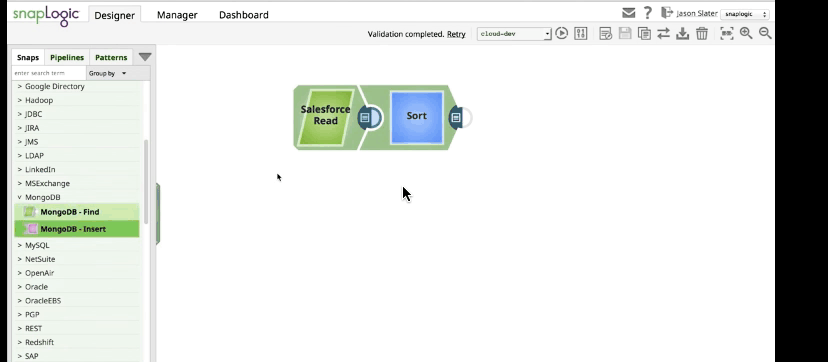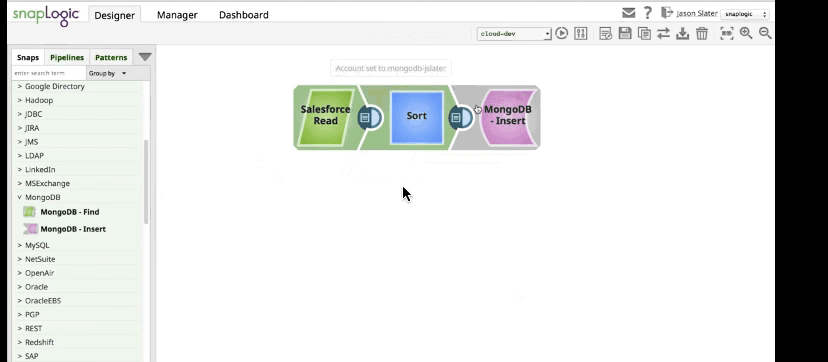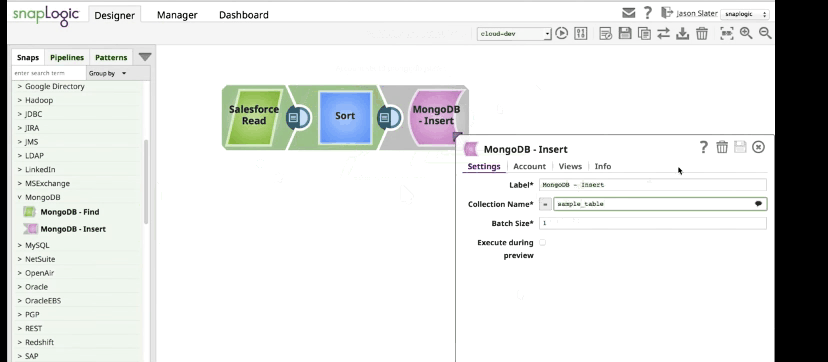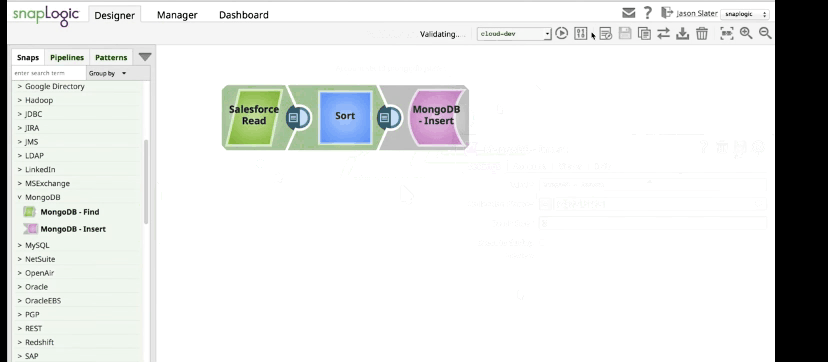
The SnapLogic Elastic Integration Platform connects your enterprise data, applications, and APIs by building drag-and-drop data pipelines. Each pipeline is made up of Snaps, which are intelligent connectors, that users drag onto a canvas and “snap” together like puzzle pieces.
These pipelines are executed on a Snaplex, an application that runs on a multitude of platforms: on a customer’s infrastructure, on the SnapLogic cloud, and most recently on Hadoop. A Snaplex that runs on Hadoop can execute pipelines natively in Spark.
The SnapLogic data management platform is known for its easy-to-use, self-service interface, made possible by our team of dedicated engineers (we’re hiring!). We work to apply the industry’s best practices so that our clients get the best possible end product — and testing is fundamental.
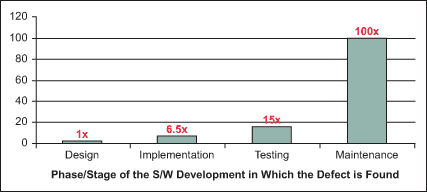
While testing is an important part of the software development process, it’s often difficult to do correctly. Some of the challenges developers face while testing software is making sure there is adequate test coverage as well as keeping test code up to date with the latest changes. Even if tests exist and are up to date, then it is possible that the tests are written incorrectly and not evaluating the code correctly. A joke that went around the Internet last year was the following picture with the caption: “All tests pass.”

Joke: probably Keith Smiley (@SmileyKeith) on Twitter
Testing helps to ensure the quality of software–but that all depends on well written tests. A poorly designed test gives false confidence that the application is working correctly, wasting time and impacting production.
From a developer’s perspective, being able to quickly iterate on implementation can greatly improve productivity. This is especially true when running programs on distributed infrastructure with a large overhead. So when developing a test framework, SnapLogic wanted to provide a means for our engineers to quickly and confidently develop a Snap, as well as for the test environment to resemble how the Snap would run in production.
Catching Gaps in Test Coverage: Snaps on the Apache Spark Platform
At the moment, Snaps are Spark-enabled by writing a method that uses the Spark RDD API in order to perform the Snap’s logic.

In general, the RDD API contains operations, which the developer calls with a function. Because of this, a Spark implementation will require the developer to get the RDD from the previous Snap, apply an RDD operation with a function, and then write the RDD to the next Snap. For example, the Java code for a filter Snap would look like this (although this is a simplified version of the actual implementation excluding logic for dealing with the expression language):
public void sparkExec(final ExecContext execContext) {
JavaRDD<Document> javaRDD = execContext.getRDD();
JavaRDD<Document> filteredRDD = javaRDD.filter(new FilterDocuments(filter));
execContext.setRDD(filteredRDD);
}
public class FilterDocuments implements Serializable, Function<Document, Boolean> {
...
@Override
public Boolean call(final Document document) throws Exception {
return shouldFilter(filter, document);
}
}
The class FilterDocuments implements the function used by the sparkExec method, which calls the Spark RDD’s filter operation with that function and the RDD passed in from the upstream Snap.
Testing this code is relatively straightforward–the actual meat of the logic is encapsulated in the function–so adding unit tests that call the filter function should be enough, right? As it turns out, there was a fair amount of logic within the sparkExec methods of some Snaps (although not in the example above), in which no automated test coverage was implemented.
100% test coverage is nice in theory, but in practice can lead to maintenance issues. A potential way to cut down on test maintenance is to skip boilerplate types of code, like most sparkExec methods. This gap in our coverage that was discovered by additional testing, but it’s cheaper to catch bugs earlier in the development cycle.
Closing the Gaps
On first glance, this problem has a few potential solutions:
Mock the Spark Framework
One option would be to mock the Spark framework, which would achieve the ability to develop quickly and automate tests. However, mocking code in tests can be brittle and a pain to maintain; plus, this wouldn’t achieve the second goal of giving confidence that the code will run the same when in a distributed mode.
Execute on Cluster
On the other extreme, the framework could require the developer have access to a Spark cluster in order to execute tests, but this would be operationally expensive to set up and maintain as well as slow the development cycle down.
Best of Both Worlds: Testing in Spark Local Mode
Our solution settles on a middle ground that takes advantage of Spark local mode. A Spark program can be written to run on a single machine, which resembles how a Spark program executes on a cluster, but without the overhead. The way this is done is providing a utility method that returns a Spark context, which is done like this.
public class SparkTestUtil {
private static final SparkConf SPARK_CONF = new SparkConf()
.setMaster("local")
.setAppName("unit test")
.set("spark.driver.allowMultipleContexts","true");
private static final JavaSparkContext JAVA_SPARK_CONTEXT =
new JavaSparkContext(SPARK_CONF);
public static JavaSparkContext getSparkContext() {
return JAVA_SPARK_CONTEXT;
}
...
}
That context is used by our normal Snap test framework–which can already configure and execute Snaps in normal mode–to build an ExecContext. Next, the framework is able to call the Snap’s sparkExec method with the ExecContext , which is also made accessible to the developer’s test for checking the output is correct.
Here’s an example test case using this framework with the Spark enhancements:
@TestFixture(snap = CSVParser.class,
input = "data/csv_parser/test_input_1.json",
outputs = "out1",
properties = "data/csv_parser/property_data_1.json",
runSparkMode = true)
public void testParse(TestResult testResult) throws Exception {
// Verify Standard mode result
assertEquals(ImmutableMap.of(
"First", "Test",
"Last", "Mike",
"Phone", "123-456-7890"
), testResult.getOutputViews().get(0).getRecordedData());
// Verify Spark mode result
ExecContext execContext = testResult.getExecContext();
assertEquals(ImmutableMap.of(
"First", "Test",
"Last", "Mike",
"Phone", "123-456-7890"
), execContext.getRDD("out1").collect().get(0));
The @TestFixture annotation allows the Snap developer to configure the properties, inputs, and outputs of the test, and is used to test Snaps in normal mode and Spark mode. By setting the runSparkMode to true , this will run allow the test to run in both normal and Spark mode, which allows for test case re-use.
In the end, the testing framework enables Snap developers to build and test their code quicker and more effectively, which reduces Snap development time and raises the quality of their product.
To learn more about the Snap Development process, check out developer.snaplogic.com which explains the necessary steps for developing Snaps for the SnapLogic Elastic Integration Platform.



