





Ultra Pipeline tasks are used to implement real-time web service integrations which require expected response times to be close to a few sub seconds. In the first series of posts I’ll outline some of the key aspects of designing Ultra Pipelines. In the second series of posts I’ll focus on monitoring these low-latency tasks.

Because Ultra Pipelines tools are analogous to web service request/response architecture, the following aspects should be considered in designing Ultra Pipelines in SnapLogic.
Number of Views:
Ultra Pipelines can support a combination of input and output views:
- No unconnected input view, No unconnected output view – Although a rare combination, this design could be used in a listener-consumer construct. With 0 input and 0 output views, an always running Ultra Pipeline can be used to poll and consume the documents from an endpoint, without requiring document feed from feed-master.
Use Case: Design a polling mechanism for change capture using the Idoc Listener Snap and update the Master Data table with the change. Because the documents are not received from the feed-master, the output view of the pipeline can be closed.
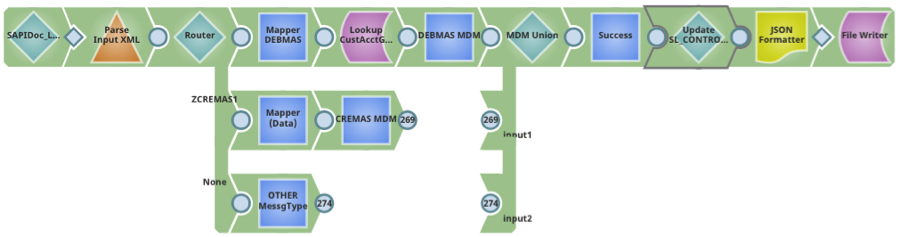
- One unconnected input view, One or more unconnected output view – The most popular Ultra Pipeline design is a straightforward request-response construct that can be used as data access layer for real-time web services. This design transforms a pipeline into an always-running job; documents are supplied to the pipeline via a feed-master that maintains a queue of documents, parsed by the pipeline and responses are returned through the feed-master to the caller.
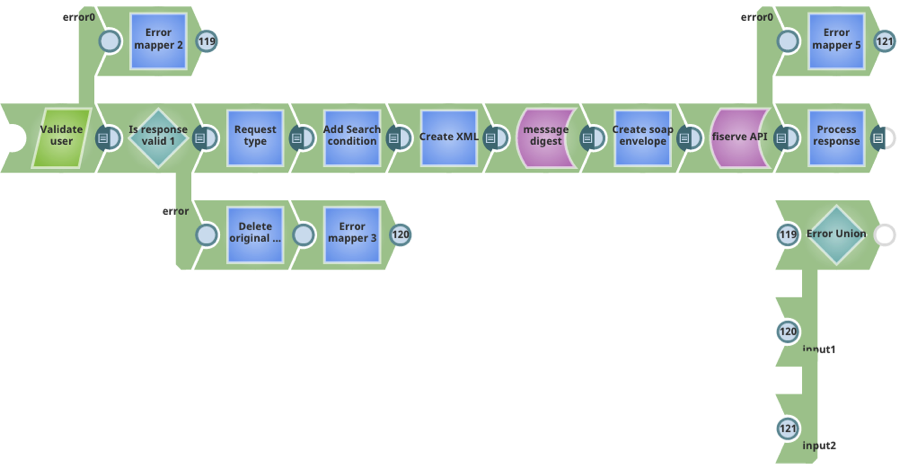
Use Case 1: Design real-time API for on-premises web-services to be used in cloud. The pipeline below uses information in the incoming document to validate the user, parse the request, call an on-premises application server and return the response. For robust processing, error handling capability and an additional output view to return errors in case of failure has been added to the pipeline design.
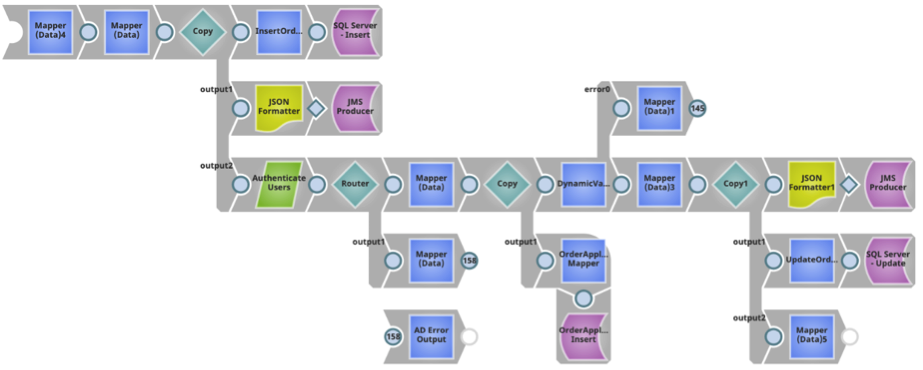
Use Case 2: A consumer endpoint can be defined by using the JMS Producer Snap to consume documents from the data feed, by creating an Ultra Pipeline with 1 input view. Because the feed-master functionality is based on a request-response framework, for every request document sent to an Ultra Pipeline task instance, the feed-master must receive a response, implying that at least one output view should be present. The Ultra Pipeline shown below reads data from an input document, parses and writes to the JMS queue, and a copy of the response is returned back to the caller.
In the next post in this series, I’ll review the types of views that are available for Ultra Pipelines. I’ll then cover error and exception handling and performance management and monitoring.
Next steps: Check out our video resources for some cool SnapLogic demos and be sure to contact us if you’re interested in learning more about SnapLogic Elastic Integration Platform.



