





 This month’s webinar was all about big data and how customers can use the SnapLogic Elastic Integration Platform and SnapReduce 2.0. In yesterday’s live discussion and demonstration, we talked with SnapLogic Chief Scientist Greg Benson, who is Professor of Computer Science at the University of San Francisco and has worked on research in distributed systems, parallel programming, OS kernels and programming languages for +20 years. The webinar went into the details of SnapReduce 2.0 for big data integration (more on that later), but first we talked about Hadoop in terms of where it’s been, where it’s going and what the implications are for traditional enterprise data warehousing. Here’s a brief recap below:
This month’s webinar was all about big data and how customers can use the SnapLogic Elastic Integration Platform and SnapReduce 2.0. In yesterday’s live discussion and demonstration, we talked with SnapLogic Chief Scientist Greg Benson, who is Professor of Computer Science at the University of San Francisco and has worked on research in distributed systems, parallel programming, OS kernels and programming languages for +20 years. The webinar went into the details of SnapReduce 2.0 for big data integration (more on that later), but first we talked about Hadoop in terms of where it’s been, where it’s going and what the implications are for traditional enterprise data warehousing. Here’s a brief recap below:
- The Big Data journey: Greg talked about early initiatives and use cases and how so much “data exhaust” was getting left on the floor.
- Hadoop and data warehousing: Many believe Hadoop and the Hadoop ecosystem will eventually replace what relational data warehouses do today because of the economics of Hadoop and what has now become possible in terms of data storage. Right now, though, they’re complementary.
- Implications on data integration: There was a good discussion about why old tech won’t work in the new era of SMAC and the variety of sources and use cases for both streaming and batch data processing.
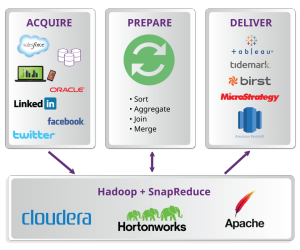
- The need to acquire, prepare and deliver big data: This includes both batch and streaming processing for a new generation of ETL/ELT.
Following the big data discussion, Greg and the team moved on to SnapReduce 2.0 and the concept of elastic scale out, with a Q&A session to address customer and prospect questions. Check out the presentation slides and questions below:
How do you make SnapLogic work across two clouds…say Salesforce in one cloud and social data in another cloud?
The first thing to understand is that the SnapLogic Snaplex respects data gravity. From this question, it looks like “services” are seen as separate clouds. SnapLogic easily connects separate services and applications and can do so either in our cloud or through a Snaplex running on premises or in a VPC. As we covered in the webinar, with SnapReduce, the Snaplex can also now run natively as a YARN application within a Hadoop cluster.
Is it possible to do transformations on data before it is actually written on to HDFS?
Yes, absolutely. When streaming data into HDFS, the data can be filtered or transformed before writing to HDFS.
Are the data flows (pipelines) converted into jar files or something like pig?
MapReduce ode is generated directly and issues to Hadoop as a jar.
Can SnapLogic directly write a .tde file for Tableau or is it a CSV file which Tableau later converts to its native format?
The SnapLogic Tableau Snap directly writes to a TDE.
Once I have read data from HDFS using HDFS Reader, would I be able to do join with data sitting on a source / database (viz. Oracle) / SQL Server)? If so, where will that pipeline run?
Yes, this can be done and in this scenario the pipeline would run in Hadoop, but on a single Hadoop node. It would not run as a MapReduce job.


