





SnapLogic’s Task Execute Snap was introduced in the Summer 2014 release. In the Fall 2014 release, the Task Execute Snap was enhanced with the addition of (transparent) compression and data-type propagation. This Snap is similar to the ForEach Snap, where a single execution of the pipeline is fired off for each incoming data document), but the Task Execute Snap:
- sends the whole input document
- can aggregate a number of input rows to stream to the target pipeline
- sends the SnapLogic data-type information across to the target, preserving date/time, numeric and string types
- compresses data as it is passed to the target pipeline for optimization of both network and memory use
The target pipeline should be configured to receive the input data (in the case of POSTing the data) or produce the data (in the case of a GET), much like a sub-pipeline, although this is even more loosely coupled. The target pipeline will be invoked once for each batch of input data. Let’s dig into some details. I’ve created three examples:
- POST-Type, where we push data to the target pipeline and expect no response
- GET-Type, where we get the output or a remotely executed task
- POST-and-GET type, where we combine inbound payload and retrieved payload
Example 1: POST-type
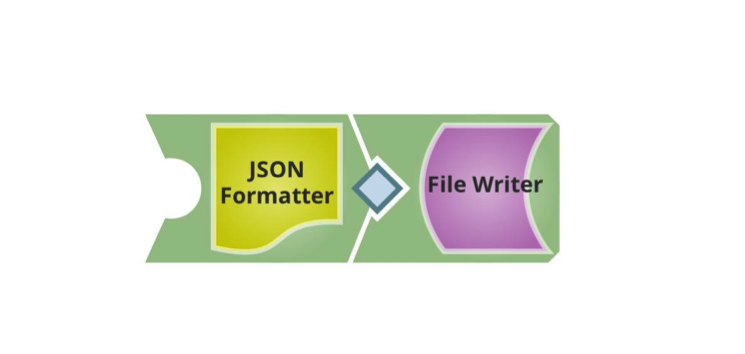
For my first example, I created a simple pipeline to consume the data, expecting it to be POSTed, as payload to the URL request, just made up of the JSON Formatter and a File Writer, although it could have been any other Snap with a document input:
And then I created a triggered task in the Manager to invoke the target pipeline:

And created a pipeline to send the data, in this case I’m selecting from my favourite Oracle database, limiting it to 50102 rows (an arbitrary number). As you see, I have configured the Task Execute Snap it to use the task I defined earlier, with a batch size of 10,000 rows, implying that it should make 6 calls, 10,000 x 5, 1 x 102. Each request is made synchronously. Note that as this is all within the same organisation, the Snap handles all of the authentication and authorisation for you.
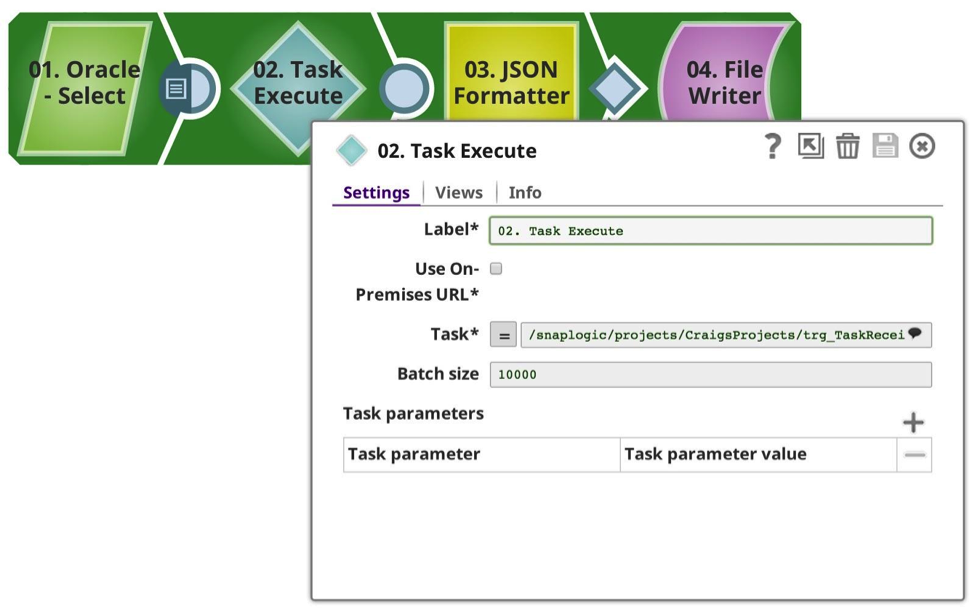
The Task is selected from the drop-down, which introspects onto the available metadata, showing on the triggerable pipelines from both the current and shared projects. (Note: If the Use On-Premises URL option is checked, it will only show those pipelines where an on-premises URL is available, i.e. running in a Groundplex.) If this option is selected, and the Snaplexes are all on-premises, no data will go out through the firewall; it would all remain secure between the nodes locally.
The Batch size can be adjusted to your requirements, balancing the load and memory usage. Each pipeline invocation does have a certain overhead in preparing, executing and logging, and this should be considered if you are using a low number of rows in batch. The higher the number of rows per batch, the higher the memory consumption.
When I run the pipeline, the data is streamed from the source, in this case into the task execute, which with the batch size set to 10,000, aggregated in memory until it either completes the input stream, or reaches the batch size, when it then sends the data to the target pipeline with the data payload.
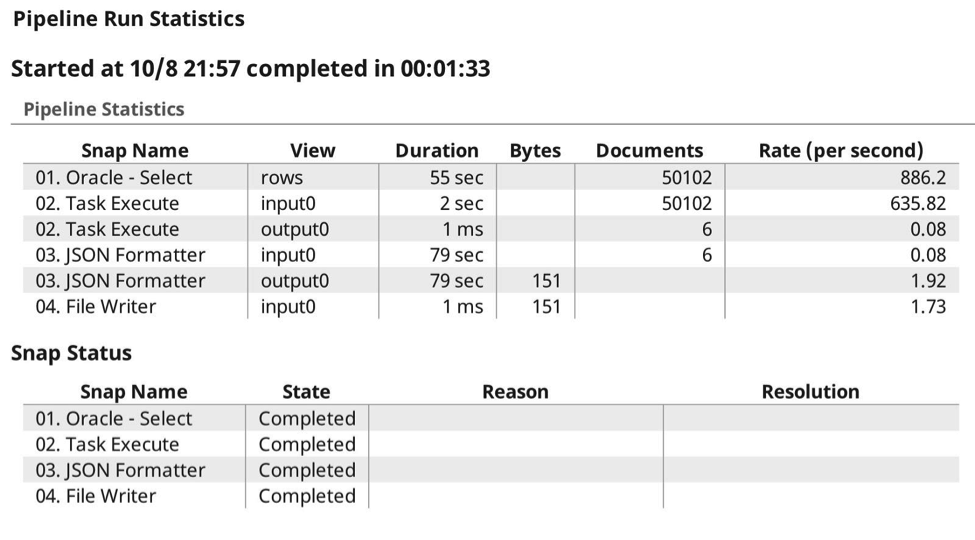
Here is the execution run log, where you can see the expected 6 calls, where it has passed the data to the target task, as expected, compression taking place automatically as it knows it is able to gzip the content and preserve the data types.
The output of the Task execute is just the HTTP return code given by the target pipeline:

This is shown in the Dashboard pipeline display as follows:

Example 2: GET-Type
In this example, I have changed the first pipeline to remove the input view, and just execute the target task and receive its output data.
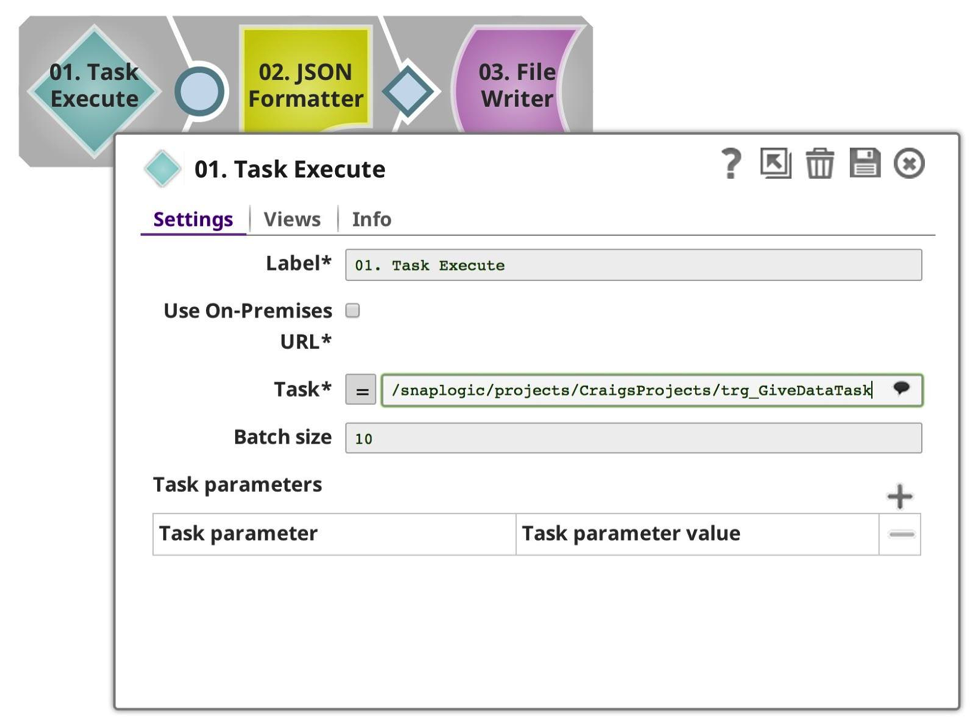
In this case, the batch size is irrelevant. Next, I changed the called pipeline to be my data producer:
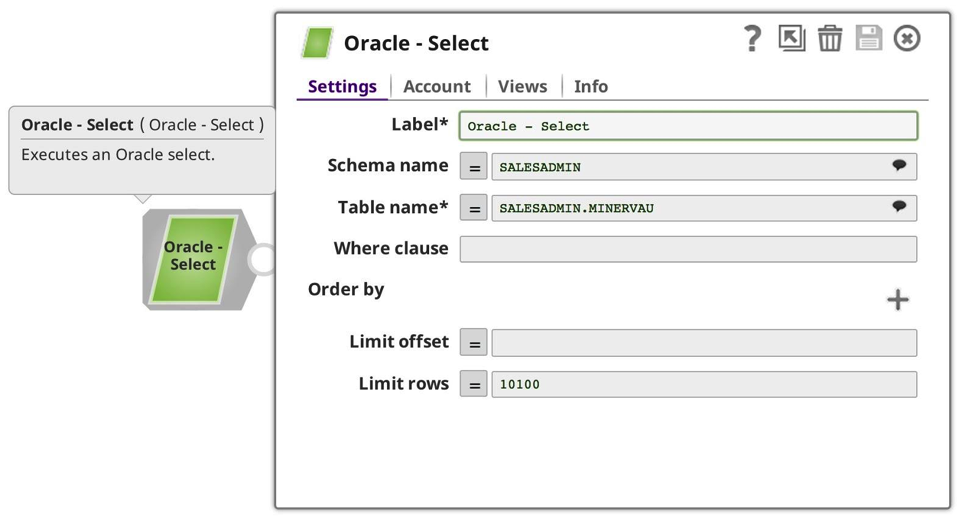
This time, the result is a smaller set of data out of my Oracle database. Next, I created a new Task, this time to my smaller, producer pipeline:
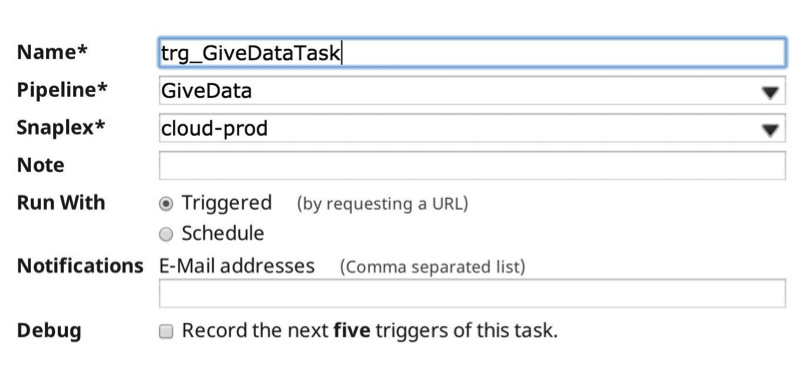
Now, when I execute the pipeline the run-time stats are as follows:
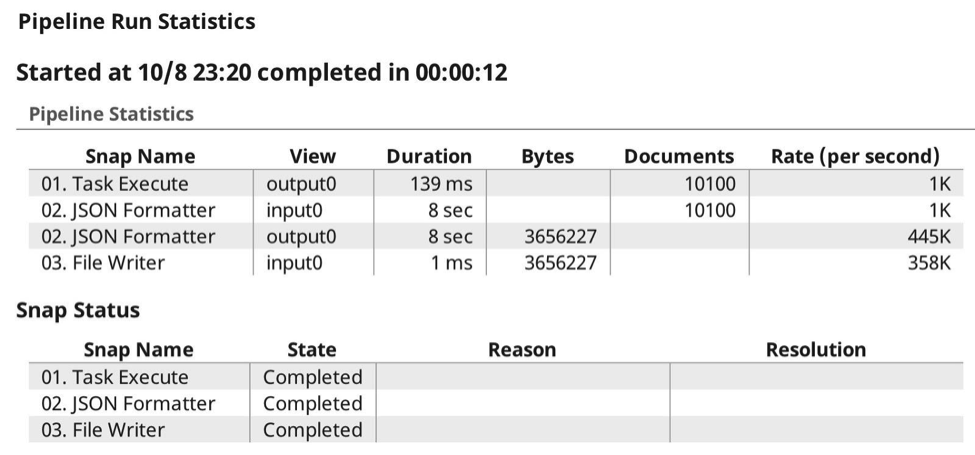
And from the Dashboard Pipeline Display is as follows:
![]()
Example 3: POST-and-GET-type
The Executed pipeline can also be a data producer. In this example, I am using the same type of calling pipeline, although this time I limited the Oracle SELECT to 52 rows of data. The Driving pipeline looks remarkably similar:
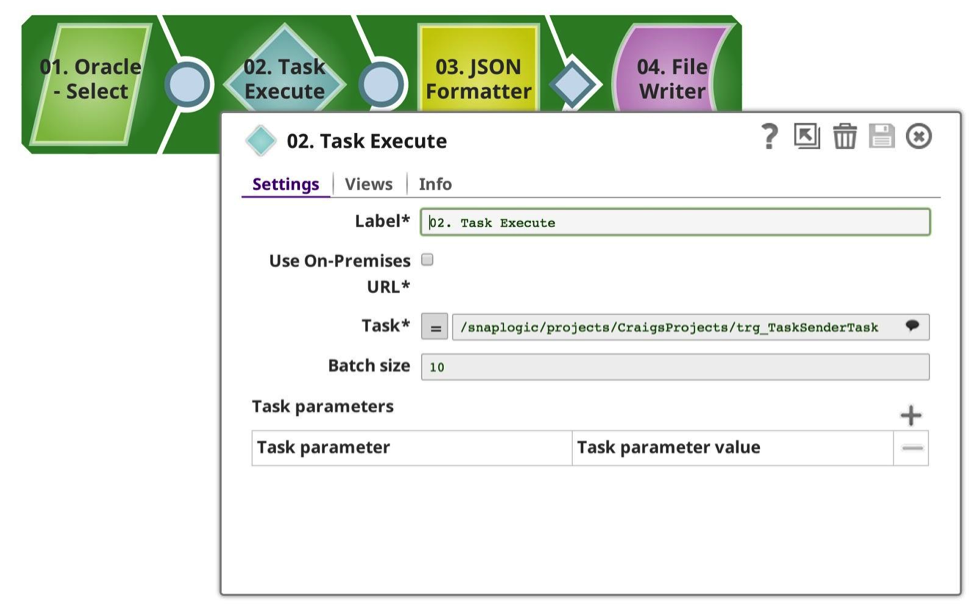
Notice how you see I have a different target URL, and a much lower batch size. In the Executed pipeline this time you can see it has an input stream, which will take the inbound payload, and in this case double data, by copying and unioning the result. Then it has an unterminated output, which will be returned to the caller.
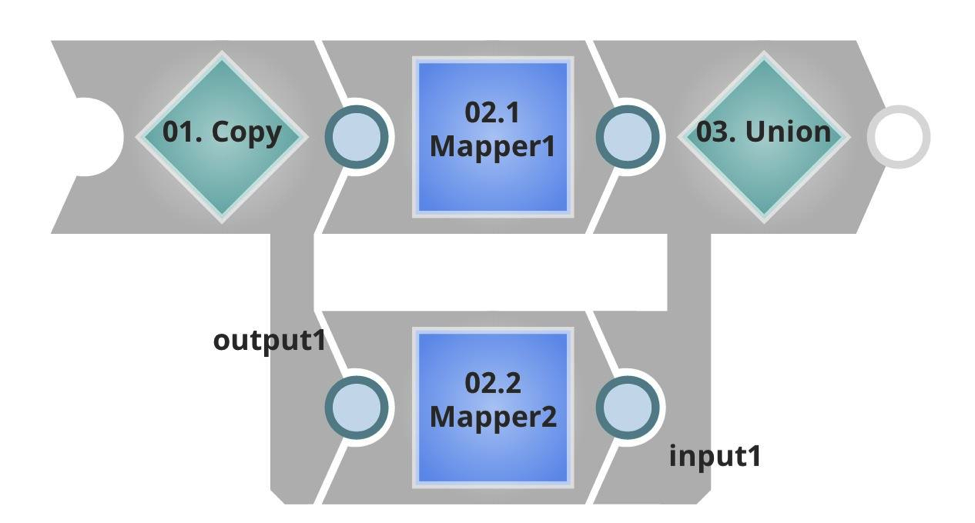
Again I created a task for it in the SnapLogic Integration Cloud Manager:

Now I have the complete set, the idea of this configuration is that I select a set of data out of my Oracle database, in this case 52 rows, which I then send in batches of 10 to the target pipeline, taking the benefit of passing the data types, compression, etc. as described previously. But this time I will actually get a result set streamed back, again preserving data types and formats.
Here are the run-time execution stats:
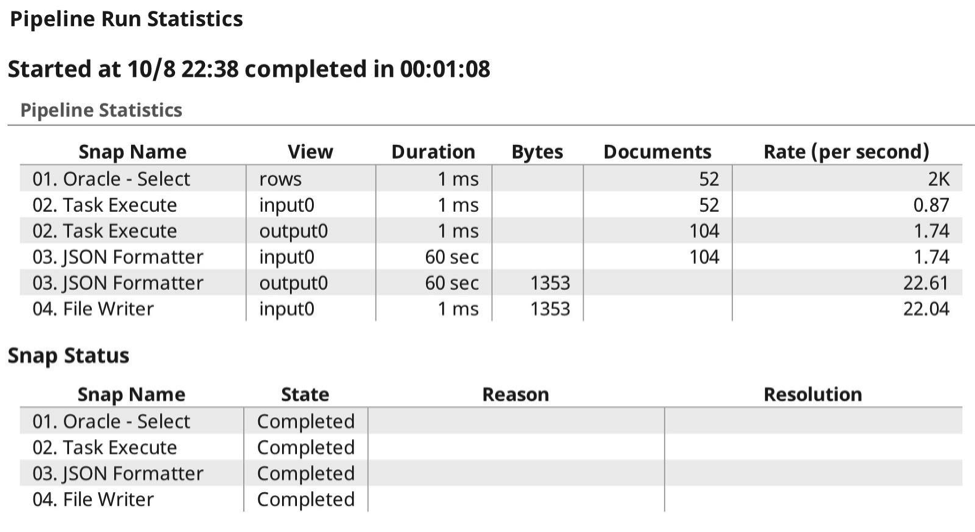
As you can see, this time I both sent and received payloads, allowing the SnapLogic Elastic Integration Platform to handle the authentication, authorisation and payload compression. No messing with headers or any other additional configuration. Here, you see the execution from the Dashboard Pipeline Display:

Summary
In summary, the Task Execute Snap enables you to pass batches of data to and from target pipelines, automatically aggregating, authenticating, compressing the data payload, and waiting for successful completion. For more SnapLogic best practices and tips and tricks, be sure to check out our TechTalk webinars and recordings.






