






We are excited to announce the general availability of the February 2019, 4.16 release of the SnapLogic Intelligent Integration Platform (IIP). This release includes enhancements to our SnapLogic API Management, SnapLogic eXtreme, and SnapLogic Data Science offerings, a new platform capability called Resumable Pipelines, and updates to popular Snaps such as the Salesforce, NetSuite, and Snowflake Snaps.
In our November 2018, 4.15 release, we launched many new offerings and platform enhancements largely based on feedback from our customers and key integration trends that we saw in the industry. In addition to launching SnapLogic API Management, SnapLogic for B2B Integration, and SnapLogic Data Science, we also introduced the Data Catalog.
Here’s a quick recap. SnapLogic API Management enables API design, creation, and management. SnapLogic for B2B Integration enables customers to automate key business processes with external partners. SnapLogic Data Science is a new self-service solution that accelerates the development and deployment of machine learning (ML) models with minimal coding. The Data Catalog provides organizations improved data governance by enabling better visibility and transparency into their data.
We look forward to having our customers leverage the SnapLogic Intelligent Integration Platform to automate all stages of IT integration projects – design, development, deployment, and maintenance – so as to drive productivity, lower the total cost of ownership (TCO), and achieve a faster time-to-value.
SnapLogic API Management: Optimize your API strategy with a complete digital ecosystem
In the February 2019 release, we have further enhanced the SnapLogic API Management interface and capabilities. SnapLogic API Management empowers organizations to build a digital ecosystem by securing, exposing, managing, and monitoring APIs for internal or external consumers while abstracting backend systems.
![With the SnapLogic IIP [an integration platform as a service (iPaaS)] and SnapLogic API Management in a unified platform, users can create, publish, manage, and monitor APIs.](https://www.snaplogic.com/wp-content/uploads/2019/02/SnapLogic-IIP-manager-view.png)
Watch the SnapLogic API Management video or register for the SnapLogic API Management webinar to learn more.
SnapLogic eXtreme: Speed up and gain insights from your big data initiatives
Since the launch of SnapLogic eXtreme in August 2018, we have seen a spike in the number of customers implementing big data initiatives using SnapLogic. We continue to build new capabilities to support SnapLogic eXtreme – our big data offering in the cloud – to further help our customers gain insights rapidly and speed up their data-driven project implementations. New capabilities include:
- The ability to use a combination of on-demand and spot instances to gain optimal cost management of big data resources, resulting in a lower TCO
- The ability to use existing PySpark scripts and Spark Java JAR programs, increasing productivity and eliminating the need to rebuild pipelines
- The ability to load data into Snowflake directly and extract data from Snowflake all in a Spark mode pipeline, thereby improving integrator productivity
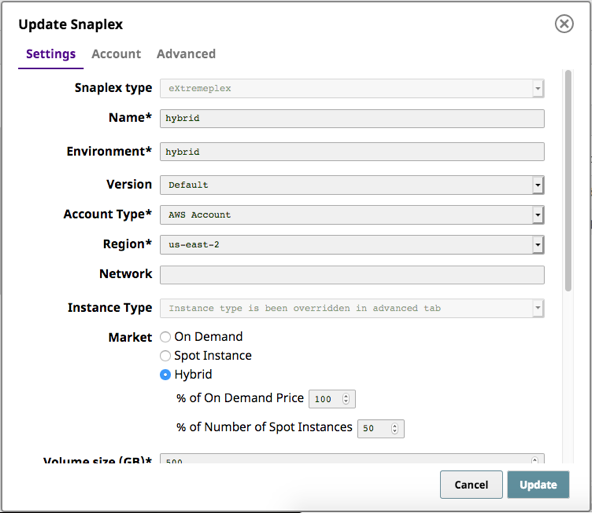
Watch the SnapLogic eXtreme video to learn more.
SnapLogic Data Science: AutoML helps democratize model development
Building machine learning models from beginning to end with SnapLogic Data Science is now within reach for citizen data scientists. With SnapLogic’s unified platform, customers with little-to-no technical background can collect and prepare data from multiple systems and applications, use the data to test algorithms, and train machine learning models. We are committed to continuously enhancing our offerings with self-service so that data and insights are democratized.
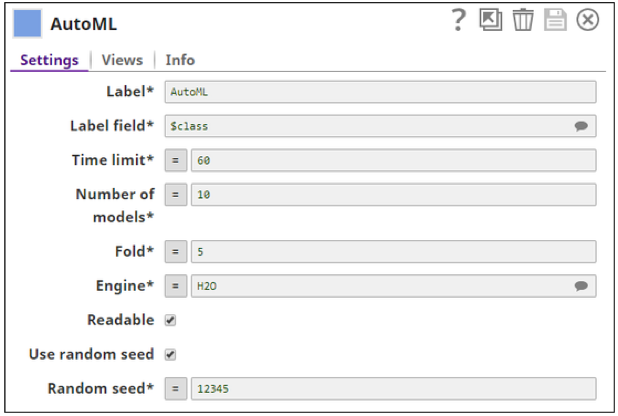
The Auto ML Snap, which is included in the ML Core Snap Pack, helps automate the process of training a large selection of candidate machine learning models by providing minimal inputs. It helps automate the process of selecting machine learning algorithms and tuning hyperparameters and gives the best predictive model within the specified time limit. Citizen data scientists can build ML models and obtain insights with much less effort, thus increasing their productivity.
We also launched the new Natural Language Processing (NLP) Snap Pack to allow users to perform operations in natural language processing. The NLP Snap Pack allows data scientists and data engineers to use NLP-based data to build ML models. When used concurrently with other Data Science Snap Packs, customers are able to gain richer insights.
For example, organizations can understand customer sentiment across their social media and review sites so they can improve customer engagement and experiences.
The Snaps in the NLP Snap Pack include:
- Tokenizer: Converts sentences into an array of tokens
- Common Words: Finds the most popular words in a set of input sentences
- Bag of Words: Vectorizes sentences into a set of numeric fields
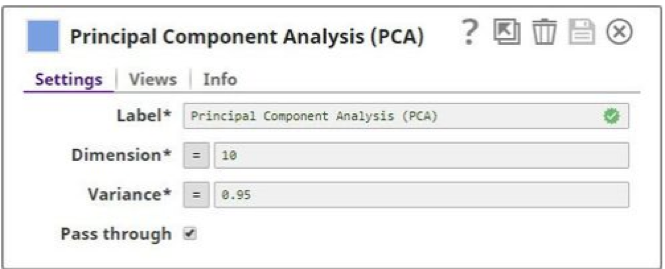
The Principal Component Analysis, or the PCA Snap, has been introduced as part of the ML Data Preparation Snap Pack. This Snap helps data engineers perform principal component analysis for dimensionality reduction. Dimensionality (attribute) reduction is very useful when you have obtained data on a large number of attributes and believe there is some redundancy in those attributes. Redundancy means that some of the attributes are correlated with one another, possibly because they are measuring the same construct. The PCA Snap makes it possible to reduce the observed attributes into a smaller number of principal components (artificial attributes) that will account for most of the variance in the observed attributes. The key benefit of the PCA Snap is that it boosts the productivity of data scientists and data engineers.
Watch this video to learn more about the SnapLogic Data Science updates.
Additional platform and Snap enhancements
- Resumable Pipelines: Having guaranteed data delivery is integral for many of our customers’ businesses. Resumable Pipelines provide an alternate method to pipeline resiliency and allow data processing in an exactly-once guaranteed delivery mechanism for a low volume of data. Instead of failing a pipeline and needing to restart the process from the beginning, the pipeline is in a suspended state until a network or endpoint failure is fixed and execution is resumed. Watch video to learn more about Resumable Pipelines.
- New Salesforce Snaps: We received feedback from a number of customers who said they wanted to leverage Salesforce (SFDC) Platform Events to allow users to send and receive real-time messages in SFDC. Platform Event fields are defined in Salesforce (custom objects) and determine the data that you send and receive. We have introduced new Salesforce Publisher and Subscriber Snaps to help organizations improve their level of customer engagement and service. The Salesforce Publisher and Subscriber Snaps provide business users with up-to-date information on Salesforce events such as a change of forecasted Opportunity amount or a change in product pricing. This enables you to quickly take action and customize customer engagements for better customer experiences. Watch this video to learn more about the SnapLogic Publisher and Subscriber Snaps.
- Enhanced Snowflake Snap Pack: In addition to Amazon S3 support, users now have the option of using Azure Blob storage for their Snowflake deployments.
- Upgrades to the NetSuite Snap Pack: Organizations can seamlessly expose and reflect the same custom fields whenever NetSuite is connected with other applications and systems.
- Added retry capability: Many Snaps now have retry capability so that pipelines can be automatically re-executed in the case of a network failure. The Snaps with added retry capability include Salesforce Read, Salesforce SOQL, Amazon Redshift, Oracle, SQL Server, MySQL, Postgres, and JDBC.






